In nine years of application design, I realize users do not like data entry. It is more painful with repeat data. This is not just an obvious blanket observation, but a theme from two formal user interface (“UI”) tests with graduate students, professors, and teachers. One of my conclusions from their work is the adoption of my technology depends on how fast users create the results – learning and job labels.
The best way to speed up the process is to limit ‘data entry’. In fact, this was one of the key inspirations in creating the learning labels in the first place. I wanted for a single person to create a label, then everyone else gets to use the label in a tasking application. But through the UI testing and watching the creation process, that single person included, does not want to spend much time entering data when he or she can get it from other sources. This was one of the motivations in creating the skills parser (another big motivation is getting better accuracy).
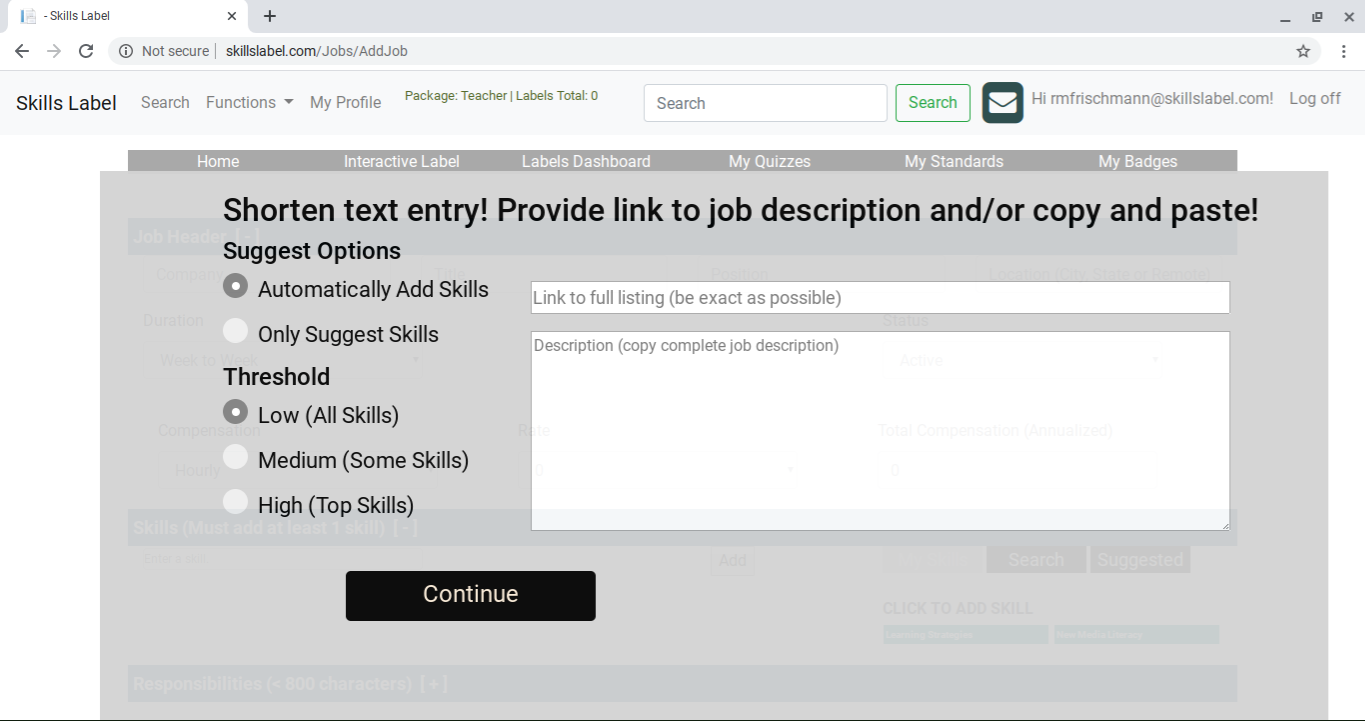
In previous sections, I introduce the parser for job descriptions. There is significant new functionality, such as ranking and parsing a URL. Typically, a learning label should have between four to six skills and no more than ten skills. A job label might include between ten to fifteen skills and no more than twenty skills. The ceiling is set to maintain clarity and precision in representing the skills. So, a parser not only helps in identifying skills but also choosing which ones to add by ranking them.
The parser accepts a URL (website address) and/or a block of content, which gets added by copying and pasting or uploading a file. So, a learning practitioner creating a learning label might use a lesson plan or review, task sheet, or project description. A job poster or recruiter creating a job label might use a job description, job definition (in an employee handbook), or ideal resume. Currently, the parser supports job descriptions as a URL from each of the top job boards.
The parser reads the content/context and returns a ranked list of skills. It accepts two parameters: suggesting or adding the skills automatically; and setting a threshold from low to high. Suggesting is helpful for working through a large set of skills (low threshold) and choosing the most relevant ones. Selecting to add skills automatically works with a medium or high threshold.
Parsing a URL works well with the job boards that provide a single page for the job, like Dice. With Indeed and Monster, finding a page with only a single job is more challenging; therefore, at this stage, copying and pasting from the page gets more accurate results. Though this is an early iteration of the parser; later, the algorithm should get better in accepting URLs.
With suggestions, a section is provided with skills sorted by rank; a user simply clicks on element to add the skills to the label. When automatically added to the label, the skills appear in a rank order; a user goes through the list and might delete or add skills and change the order the skills.
This is an early iteration of this feature. My team plans to significantly advance the skills parser with better rankings, more precise results, and add more elements from the parser onto the labels.